
CONTACT
お問い合わせ
導入に関する質問やご相談、サポートに関することなど、まずはお気軽にご相談ください。
ビッグデータ|データエンジニアリング|モダンデータスタック|クラウドネイティブ|BI|AI
企業がデータを活用して価値を生み出すためには、まず“データを使える状態にする”ための基盤づくりが欠かせません。
この基盤づくりを担うのがデータエンジニアリングです。データエンジニアリングとは、組織内外に散在するデータを収集し、整形し、信頼できる形で蓄積・管理することで、分析や意思決定に活用できる高品質なデータを提供する技術分野です。
近年、ビッグデータやAIの普及に伴い、企業が扱うデータ量は飛躍的に増加しています。
その一方で、「データがバラバラで活かせない」「分析に時間がかかる」「必要なデータが取得できない」といった課題も顕在化しており、データエンジニアリングは 企業のデータ活用戦略を支える中核領域 として重要性を高めています。
データエンジニアリングの最も大きな目的は、データドリブン経営の実現を支えること です。
データに基づいて迅速かつ正確に意思決定を行うこの経営手法は、今日の競争環境において企業の成長と競争力向上に直結しており、多くの企業が積極的に導入を進めています。
企業のデータ価値を最大限引き出すため、データエンジニアリングでは以下の領域を体系的に整備します。

大量データを効率的かつ安全に蓄積・管理するため、データウェアハウスやクラウド基盤などのシステムを設計・構築します。高速処理やスケーラビリティを実現し、日々の運用も含めて安定したデータ活用を支援します。
複数システムに散在するデータを収集し、重複や表記ゆれを解消しながら分析に適した形に整えます。これによりデータ品質が向上し、分析スピードや精度を大きく高めることができます。
AI が正しく学習するためには、高品質な教師データが不可欠です。データエンジニアリングでは、AIモデルの学習や改善に必要となるデータを整備し、継続的な性能向上を実現します。
当社は長年の経験と専門チームにより、データ活用を包括的に支援できる体制を備えています。

多様な業界・規模のプロジェクトで培った経験をもとに、最適なアーキテクチャ設計や移行方針を提示できる点が当社の大きな強みです。
データの整備から基盤構築、活用フェーズまで一貫して支援してきた実績により、技術面だけでなく「実務で本当に役立つ仕組み」を提供できるノウハウが蓄積されています。

データ収集・加工・蓄積、分析、BI、AI といった全工程を、自社内の60名超の専門技術者が横断的に対応します。工程ごとに担当が分断されないため、設計思想のブレがなく、品質の高いデータ活用基盤を統合的に提供可能です。
お客様の体制や課題に合わせた柔軟なチーム編成ができることも大きな特徴です。

Snowflake、Databricks、Amazon Redshift、BigQuery などを活用したモダンデータスタック構築に強みがあり、高速性・拡張性・運用性を兼ね備えたデータパイプラインを実現します。
また、AWS / Azure / GCP などクラウド環境に最適化したアーキテクチャ設計により、将来的なデータ量増加や新規システム連携にも柔軟に対応できます。
TableauなどのBIツールに精通したエンジニアが、ダッシュボード構築から分析業務の支援まで丁寧に伴走します。さらに、AIモデルの学習に必要な教師データの整備や運用プロセスの構築まで含め、データ活用が企業内で継続的に回る状態までサポート。単なる基盤構築にとどまらず、「活用して成果を出す」フェーズまで一緒に推進します。
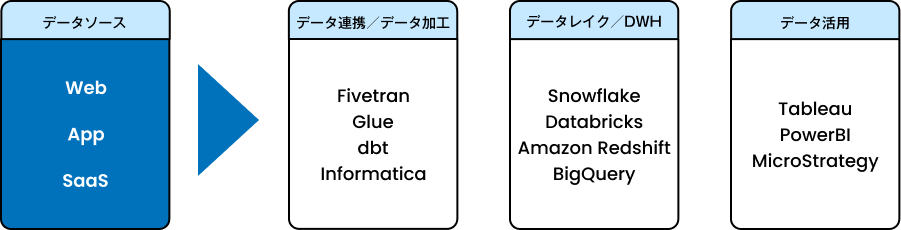
当社は、データ収集から基盤構築、分析・AI活用まで、データエンジニアリング領域を幅広く支える製品・サービスをご提供しています。当社がカバーする製品・サービス領域を体系的にまとめています。
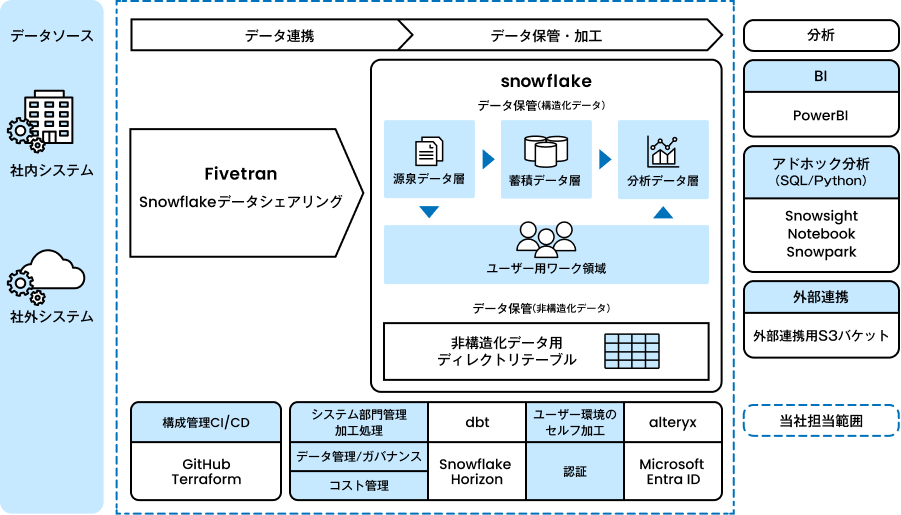
既存の分析基盤では、利用者側の「データ利活用の柔軟性・俊敏性」、システム側の「要件変化への対応力」に課題があり、ビジネス要求へのスピーディな対応が難しい状況でした。
当社は、これらの課題を解消するために、柔軟性と拡張性を兼ね備えた新たな分析基盤の構築を担当しました。
本プロジェクトでは、データ連携からデータ保管・加工までを担う基盤層の設計・実装を中心に、基盤チームの一員として参画。データ整備・利活用チームと密に連携しながら、要件定義フェーズから開発・検証まで一貫して支援しました。
これにより、利用者が迅速にデータを活用できる環境を整備し、ビジネス変化に強いデータ基盤の実現に貢献しています。




近年、企業のデータ基盤において、モダンデータスタックという考え方が注目されています。本コラムでは、モダンデータスタックについての説明、そしてモダンデータスタックの製品群に属する「Fivetran」「dbt」という2つの製品についてご紹介します。
お問い合わせ
導入に関する質問やご相談、サポートに関することなど、まずはお気軽にご相談ください。