
CONTACT
お問い合わせ
導入に関する質問やご相談、サポートに関することなど、まずはお気軽にご相談ください。
Databricks|Bigdata|ビッグデータ|AI|生成AI|DX|Data Lake|データレイク|レイクハウス|DWH|機械学習|RAG|AIエージェント
ビッグデータ領域における構築・開発について、当社はこれまでデータの可視化と機械学習モデルの開発を別々のプラットフォームで提供するしかありませんでした。そのため、両方の機能を利用したいお客様からは、プラットフォーム間の連携を強化してほしいというニーズが多く寄せられていました。
Databricks では BI の環境と AI の環境をオールインワンで提供しています。プラットフォームが統合されているため、各機能間の連携が容易です。期待する分析データや洞察を素早く得ることができるため、ビジネスの意思決定のスピードを向上させることができます。
当社では Databricks のプロフェッショナル集団として、ビッグデータ分野の経験豊富な人財を保有し、各種サービスをご提供しています。
Databricks は、クラウド上でデータの収集・蓄積からデータの可視化、 AI 活用まで実施できる統合プラットフォームです。
これまでデータ分析環境の構築にあたっては、データウェアハウスやデータレイク等のデータ基盤整備、BI ツールによる分析画面の作成、さらには AI 利用のためのデータ加工といった構成要素を複数の製品を利用して構築・連携しなければならず、分析システムのスムーズな運用に向けては、データ品質・鮮度の保証、データガバナンスの確保、複数製品利用環境におけるトラブル時のリカバリの難しさなどの課題がありました。Databricks では一連のデータエンジニアリングの流れを統合的に管理することで、このような課題を解決いたします。
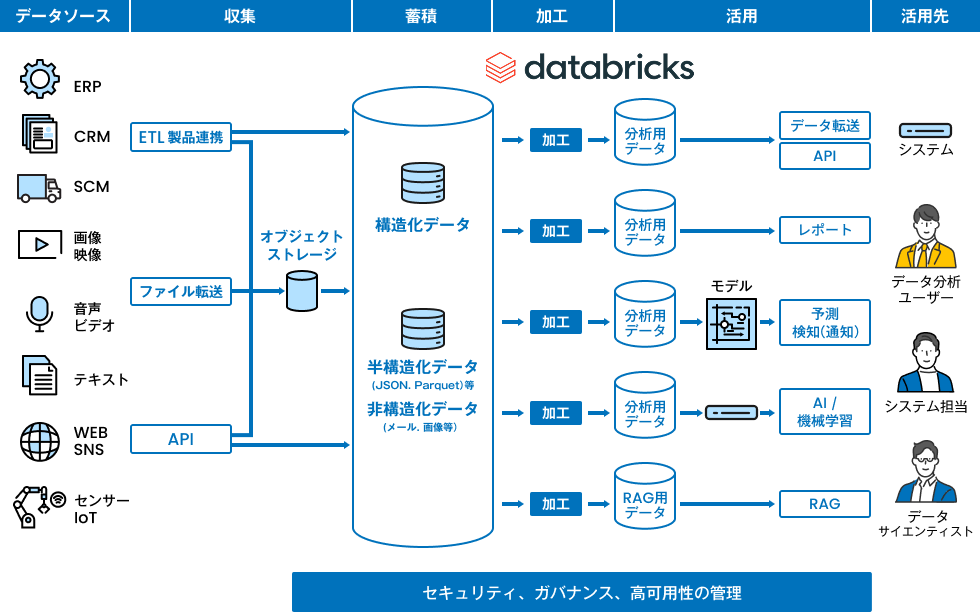
Databricks は、データの収集から活用までのプロセスを簡単に一元化できます。クラウド上でデータ分析環境を構築し、データの収集や加工、連携、管理を最適化することが可能です。
■ リアルタイムでデータ収集から活用までを処理
ストリーミング処理により、0.5秒というリアルタイムに近い間隔でデータの収集、変換、および機械学習モデルの作成が可能です。
■ 機械学習のライフサイクルの一元管理
Databricks は、機械学習の実験から本番までのライフサイクルを一元的に管理できます。モデル開発の際に必要なデータが自動で記録され、分析・検証も容易に行えます。
これらにより、意思決定の際に即時に更新された情報を利用することで、意思決定品質の向上を実現できます。
■ データ処理のスケジューリングと管理
Databricks は SQL や Python を利用した ETL 処理のワークフローのスケジューリング機能を提供します。データの収集、変換、クリーニング、蓄積などのプロセスを効率的に管理できます。
■ ダッシュボードとビジュアライゼーションの生成
データの可視化に役立つダッシュボードやグラフを作成できます。Databricks 上で直接データを探索し、ビジネスの洞察を得ることができます。
■ セキュリティー、ガバナンス、高可用性の管理
データの安全性や可用性を確保します。Databricks のデータと AI 資産の統合ガバナンスソリューションである Unity Catalog の機能では、監査、リネージ、データ検出、アクセス権限制御が実現します。
■ データの検出、アノテーション、探索
データの探索や分析をサポートします。データの特定やアノテーションを効率的に行えます。
■ 機械学習 (ML) のモデリング、追跡、モデルサービング
機械学習モデルの開発から運用までをサポートします。モデルのトレーニング、評価、デプロイを効率的に行えます。
■ 生成AI /AIエージェント
Databricks 基盤モデルまたは外部のモデルを活用し、Chat、プロンプトエンジニアリング、検索拡張生成 (RAG)、AIエージェントを構築し、ファインチューニング、事前トレーニングなどをサポートします。
■ Serverlessコンピュート
Databricks SQL では Serverless コンピュートにより、効率的なスケーリングやコンピュートの多重度に対応します。
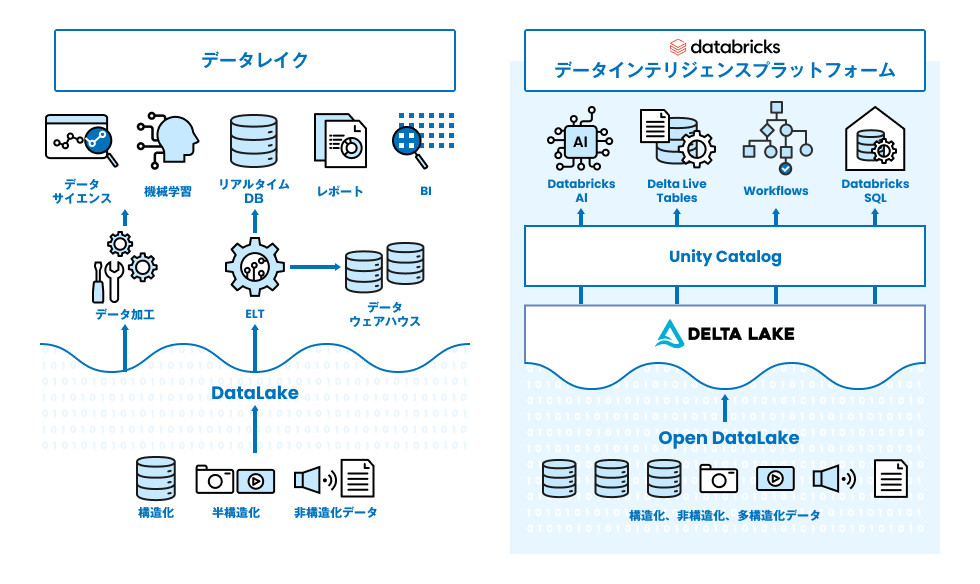

当社では Databricks を活用してデータの収集・蓄積から分析・機械学習モデルの開発まで、End to End の開発・運用を支援しています。
当社には「Solutions Architect Champion」資格をはじめとする Databricks 資格保持者が在籍しています。また、Tableau 等の BI ツールや、各種 DWH 製品・データレイクで長年にわたり蓄積してきたノウハウがございます。
これらのノウハウを活用し、お客様の Databricks の開発と運用をご支援いたします。
Databricks 導入時の初期構築をご支援します。Databricks の構築に関連した AWS の設定も含めて、環境構築および権限設計、設定をご支援します。
以下についての設計、実装、テストをご支援します。
以下についての設計、開発をご支援します。
以下のように特徴量エンジニアリングおよび機械学習モデルの構築をご支援します。
※ 特徴量エンジニアリングとは、機械学習モデルのパフォーマンスと予測精度を向上させるために、新たな変数(特徴量)を入力データセットに追加することです。
以下のように生成AI/AIエージェントの導入支援ご支援します。
当社の Databricks 有資格者をはじめとする ETL ・BI・Python・AWS 等の各技術者が、お客様の Databricks 導入プロジェクトに対して、 お客様にとって最適なご支援方法について、柔軟に提案してまいります。
NTTデータグループの中でも幅広い専門知識と資格保有者を有する当社。
Databricks での End to End 開発・運用は是非当社にお任せください!




Databricks を用いて、データ活用による部門横断的な会社への貢献状況を可視化し、全社への浸透を支援した事例をご紹介します。

Databricks が提供する対話型の生成AIアシスタント「Genie」は、自然言語で質問するだけで集計表やグラフを自動的に提示します。このコラムでは、Genieを使って実現できる2つの活用例をご紹介します。

Databricks Assistant の機能をご紹介しながら、データ可視化のスキルがなくともダッシュボード作成が可能であることを検証します。
お問い合わせ
導入に関する質問やご相談、サポートに関することなど、まずはお気軽にご相談ください。