ビッグデータやAI領域で活用が進むSnowflakeの解説と導入事例の紹介 ~ クラウドを活用した並列分散処理により、大量データ分析の時間とコストを大幅に削減 ~
- Snowflake
- Bigdata
- ビッグデータ
- AWS
- AI
- 生成AI
- LLM
- クラウド
- SnowProCore
- サーバーレス
ビッグデータの分析やAIアプリの構築も可能なSnowflakeの特長
Snowflakeは、クラウドベースのデータプラットフォームです。大量のデータを一元管理し、高速に分析・処理できるのはもちろんのこと、Streamlit*1を使ったアプリケーション開発も可能です。また、生成AIサービスにも注力しており、「Coretex AI」から大規模言語モデル(LLM)へアクセスし、AIアプリケーションを構築できる機能を拡充するなど、活用の幅が広がっています。
*1 PythonでWebアプリケーションを作成するためのフレームワークのこと
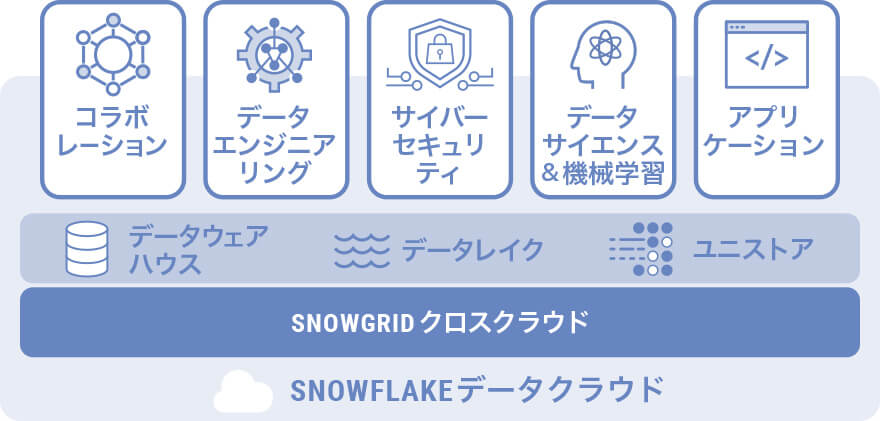
パブリッククラウドの特性をいかした優れたアーキテクチャ
一度構築したら、その後はパッチ適用の管理を行わずに、インフラ全体を特定の状態で固定化します。インフラ構成の変更等が必要な場合には、新規にインフラ環境を構築し、既存環境から新環境に全体を切り替えて運用します。 IaC(Infrastructure as Code)という手法を採用してインフラ構築をすべてコード化することにより、構築や廃棄、起動などの作業の負担を軽減することが可能となります。
一度構築したら、その後はパッチ適用の管理を行わずに、インフラ全体を特定の状態で固定化します。インフラ構成の変更等が必要な場合には、新規にインフラ環境を構築し、既存環境から新環境に全体を切り替えて運用します。 IaC(Infrastructure as Code)という手法を採用してインフラ構築をすべてコード化することにより、構築や廃棄、起動などの作業の負担を軽減することが可能となります。
運用・保守作業の負荷低減
ビッグデータ運用は、扱うデータの量が多く、データ保護にも莫大な費用を要すると思われていますが、Snowflakeを活用することで運用や保守作業を低減できます。Snowflakeには、特定の時点に戻れる機能や1つのゾーン障害に対応した保護機能が標準で提供されており、データ格納領域(マイクロパーテーション)の最適化も自動で運用できます。また、パブリッククラウドやリージョンの障害への対策として、レプリケーション機能が提供されており、比較的安価にBCP対策することが可能です。
柔軟なデータ共有と管理
Snowflakeアーキテクチャではデータをコピーせずに企業間での安全なデータ共有が可能です。また、多くのSaaSベンダーがSnowflakeデータマーケットプレイスにデータセットを提供しているため、簡単な手続きでデータにアクセスすることができます。
多くのデータを取得することにより、多様化するビジネス環境への対応が可能になります。
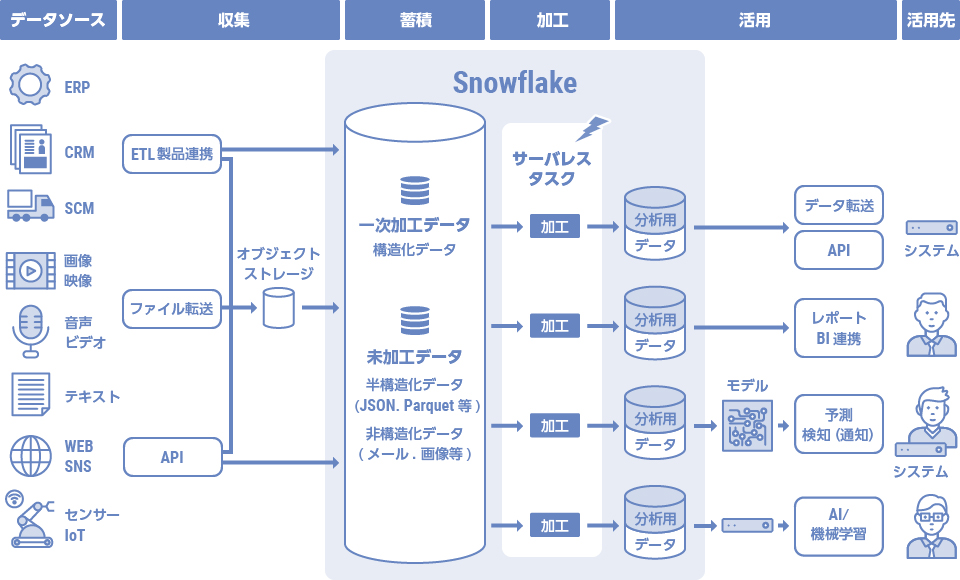
また、データ格納をELT方式にし、生データをJSON形式(VARIANT型)のような半構造化データで一旦取り込むことにより、直近では利用しない項目値に関するデータ設計を先送りすることができます。
これにより、新しいデータ種を利用者に提供するまでの時間(本番移行までの時間)を、データ変換を行ってから格納するETL方式に比べて短くできます。
そしてSnowflakeでは半構造化データ形式でデータを保持した場合でも、SQLのみならずPythonやSparkを用いてクレンジング・加工が可能です。
フレキシブルな従量課金
従量課金制のため、目的にあわせて稼働を調整し、高いパフォーマンスを保ちながらコストを抑えることができます。 複雑な処理をする時には性能を高く、それ以外の時間帯は性能を低くしたり、稼働を止めたりするなど、利用状況に合わせたフレキシブルな課金が可能です。
Snowflakeの特性をいかした環境構築で、工数やコストを削減
NTTデータ ニューソンにはSnowflakeの技術認定資格であるSnowPro Coreを保有しているメンバーが複数在籍しており、Snowflakeの特性をいかした活用方法を提案しています。データ分析基盤の構築や他システムから移行し、工数やコストの削減に繋げた事例等をご紹介します。
事例1:故障診断システムの環境構築・データ分析・維持管理(製造業のお客様)
AWSフルマネージドサービスとSnowflakeを使った診断環境の再構築をしました。
SnowflakeにはIoTログがSnowpipe*2により随時テーブルに取り込まれており、全体で1兆レコード超もの大量のデータを保持しています。
再構築前は、日々の分析バッチ処理をおこなうため、毎日数十億レコードを高価なサーバーに取り出し一晩中処理をおこなっていました。再構築時には、データを抽出する際にSnowflake側ではPythonを利用して前処理をおこない、AWS側ではLambdaで1,000並列に分散して診断処理をおこなうようにしたため、30分から1時間程度で処理が可能になりました。また、高価なサーバーを使う必要がなくなり、費用も大幅に削減できました。
本プロジェクトの対応を始めた当初は、SQLやPythonを活用した場合でもSnowflakeで細かいデータ分析をおこなうのが難しい状況だったため、SnowflakeとAWSフルマネージドサービスを組み合わせて処理をする作りとなっていました。しかし、Snowparkという機能によりSnowflake内部でSpark処理ができるようになりました。今後はSnowflakeでデータ分析を完結させ、さらなる費用低減への取り組みを進める予定です。
*2 Snowflakeのテーブルに対して継続的にデータをロードする仕組み
事例2:データ分析基盤および分析モデルの開発環境構築の支援(製造業のお客様)
ローカルに存在していたloTログをSnowflakeにインポートする独自Pythonツールを開発しました。
多数のCSV、TSVが存在し、同じデータ種でも発生時期によりカラムの数が異なるという状態だったものの、ファイルにヘッダレコードが付与されていたため、インプットファイルをJSON形式に変換する汎用的なツールを作成しました。それにより、ELT方式で、短期間でSnowflakeへ格納することを実現しました。また、汎用ツールの中でテーブル作成をする際、抽出条件で頻繁に利用するカラムはJSON外でも独立したカラムとして保持するよう、設定ファイルでコントロールできるよう工夫しました。
分析モデルの開発環境構築においては、Snowflakeと連携して特定期間のIoTログを取得してクレンジング・前処理・可視化を行うPythonの分析環境を構築するとともに、分析時間を更に短縮するためにSnowflake内で全て処理を行うSnowparkを使ったPythonの分析環境の構築も行っています。
事例3:開発の生産性向上に向けたデータ加工・運用業務(通信業のお客様)
開発の生産性を向上させるためにSnowflakeとdbtを活用したデータ加工・運用業務の支援をしました。
お客様はサービス向上のため、利用情報などのデータ分析を迅速に行う必要があり、Snowflakeを導入することで高速かつ安定したデータ分析基盤を実現していましたが、ビジネススピードが加速するなかで、データ加工におけるデータマートの開発生産性が課題となっていました。
そこで、データ変換に特化したツールであるdbtを導入しました。dbtは、実行結果を自動でテストしたり、処理フローを視覚的に確認したり、仕様書を自動生成したりといった機能が充実しており、Snowflake単体では補いきれない部分をカバーしてくれます。これにより、データ変換に関する作業を効率化し、開発のスピードアップを実現しました。
さらに、dbt.Labs社が公開しているdbtベストプラクティスに則って3つのレイヤーに分けて設計・構築するなど統一ルールを設けることにより、開発者が増えると発生しがちな品質のばらつきや教育面の負担軽減も図っています。
開発の生産性を向上させるためにSnowflakeとdbtを活用したデータ加工・運用業務の支援をしました。
お客様はサービス向上のため、利用情報などのデータ分析を迅速に行う必要があり、Snowflakeを導入することで高速かつ安定したデータ分析基盤を実現していましたが、ビジネススピードが加速するなかで、データ加工におけるデータマートの開発生産性が課題となっていました。
そこで、データ変換に特化したツールであるdbtを導入しました。dbtは、実行結果を自動でテストしたり、処理フローを視覚的に確認したり、仕様書を自動生成したりといった機能が充実しており、Snowflake単体では補いきれない部分をカバーしてくれます。これにより、データ変換に関する作業を効率化し、開発のスピードアップを実現しました。
さらに、dbt.Labs社が公開しているdbtベストプラクティスに則って3つのレイヤーに分けて設計・構築するなど統一ルールを設けることにより、開発者が増えると発生しがちな品質のばらつきや教育面の負担軽減も図っています。
今後もNTTデータ ニューソンは、Snowflakeの特性を最大限に活かす開発を支援してまいります。
執筆者

- 首藤 悠介
-
- AWS認定全冠を2年連続で受賞。2016年にニューソン入社後、クラウド環境でのビッグデータ案件をきっかけにインフラ領域を学び、クラウド・データエンジニアに転向。現在はAWSとSnowflakeを中心にビッグデータ分析環境の構築を支援。