企業のデータ活用を加速する新しい選択肢 ~ モダンデータスタックで始めるデータ変革 ~
- ビッグデータ
- モダンデータスタック
- クラウドサービス
- SaaS
- Fivetran
- dbt
- Bigdata
- 生成AI
- ETL
- データレイク
近年、企業のデータ基盤において、モダンデータスタックという考え方が注目されています。
本コラムでは、モダンデータスタックについての説明、そしてモダンデータスタックの製品群に属する「Fivetran」「dbt」という2つの製品についてご紹介します。
モダンデータスタックとは何か
モダンデータスタックとは、データ基盤における各領域の機能に特化したクラウドサービス(SaaS)を組み合わせてデータ基盤を構築する考え方・トレンドのことを指します。
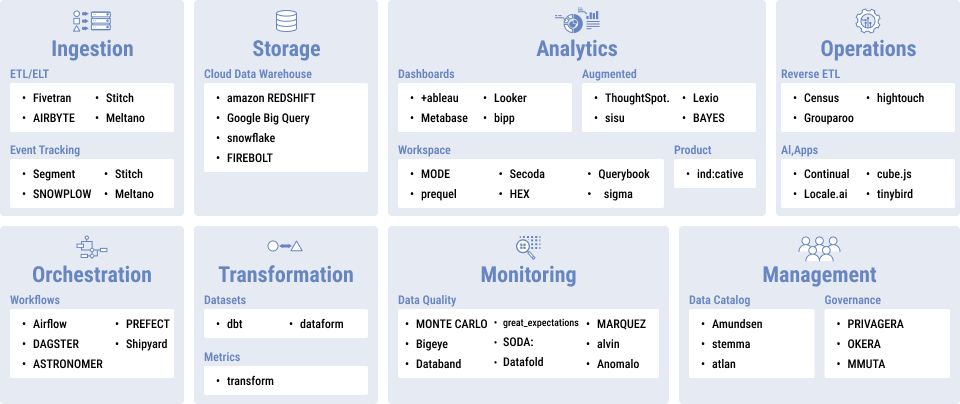
従来のデータ基盤(いわゆるレガシーデータスタック)は特定のPaaS(AWS・GCP・Azureなど)を中心に開発をされることが多く、デリバリ/拡張スピードが遅い、利用者はエンジニアが中心といった課題がありました。一方で、モダンデータスタックは、クラウドサービス(SaaS)を組み合わせることでデリバリ/拡張スピードが速い(柔軟・低コスト)、利用者はエンジニアだけでなく非エンジニアも利用可能といった利点があります。
モダンデータスタックが注目される理由
モダンデータスタックが注目される理由として、大きく以下がポイントだと考えられます。
① スピーディーに始めることができる
クラウドサービス(SaaS)のため、ソフトウェアのインストールやインフラの準備・設定といった部分に時間をかけることなくスピーディーに利用を開始することができます。
また、無料トライアル期間やフリープランを提供しているサービスも多く、「まず触って確かめてみる」といった事が可能です。
② 非エンジニアの方でも扱いやすく、業務を加速できる
UI上の操作で作業を進められるなど、ローコード/ノーコードで利用できるサービスが多く、アナリストや営業といったエンジニア以外の方もよりデータを活用することができ、現場でのデータ活用を加速させることができます。
③ スケーラブルでコストを最適化できる
多くのサービスは、導入した企業の利用状況に合わせてリソースを自動でスケーリングする設計となっており、ユーザー側は意識することなくサービスを利用することができます。
また、いわゆる従量課金モデルを採用しているため、「利用したリソースに応じたコストを支払う」ことでコスト最適化を図ることができます。
データ活用を加速させる、モダンデータスタックの中核ツール
モダンデータスタックを構成するツールは多岐にわたりますが、当社では中でも「Fivetran」と「dbt」の2製品を中心に、導入や活用を支援しています。いずれもデータ収集および加工の領域を担う代表的な製品であり、モダンデータスタックの中核を支える存在です。
以下では、それぞれの特長と活用のポイントについてご紹介します。
Fivetranについて
Fivetran社が提供するSaaS型のプラットフォーム製品で、あらゆるデータを迅速に集めてロードすることを目的として発展しました。
Fivetranは主にELTのL(ロード)の領域を担う製品となっていますが、dbtと連携してT(トランスフォーメーション)の領域を行うことも可能です。
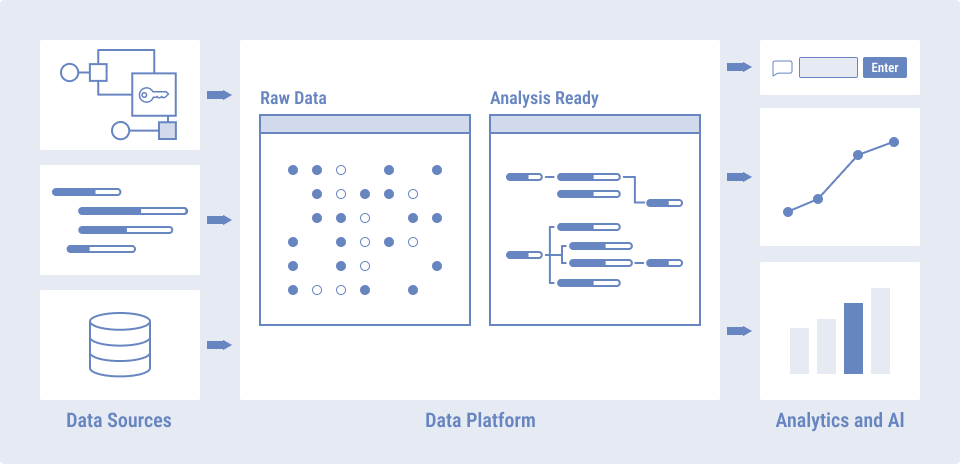
製品の特長としては、主に以下が挙げられます。
① 700種類を超える豊富なコネクタを用意
様々なデータソース(例:SaaSアプリ、データベース、クラウドストレージなど)に対応できるよう豊富なコネクタが提供されており、シンプルな手順で迅速にデータ連携の設定を行うことが可能です。
また、ノーコードで設定が行えるためエンジニア以外の方も設定がしやすく、開発コストの削減や開発効率の向上が期待できます。
② データソース側の変更・更新に対する自動対応
データソース側でカラム追加やデータの追加・更新などが発生した際に、Fivetranが自動で検知して連携先へ反映を行います。
ユーザーとしては最初にコネクタを設定する必要はありますが、1度コネクタの設定を行いデータ連携を開始すれば、任意の連携頻度で対象となるデータを自動で連携し続けてくれるため、運用負荷は大幅に軽減されます。
③ MAR(Monthly Active Rows)ベースでの料金体系
Fivetranは、データ連携されたユニークな主キーの行数が課金対象となる、MAR(Monthly Active Rows)をベースとした料金体系となっています。
1か月の中で、データ連携されるユニークな主キーの行が新規で発生するたびにMARがカウントされ、月末のMAR数値によってその月の料金が確定します。
なお、当該月の中で同じ主キーの行を何度更新しても、MARとしては重複してカウントされません。
そのため、連携頻度が高い場合に、同じ行が何度も更新される度にMARが加算され、追加課金の対象になってしまう、といった事がない点は安心できるポイントです。
また、Fivetranのコンソール上でMARをリアルタイムに把握できるため、コストの把握や利用状況の調整を行うことができます。
dbtについて
dbt Labs社が提供するSaaS型のプラットフォーム製品で、ELTのT(トランスフォーメーション)の領域を担う、モダンデータスタックの中心的ポジションとなるような製品です。
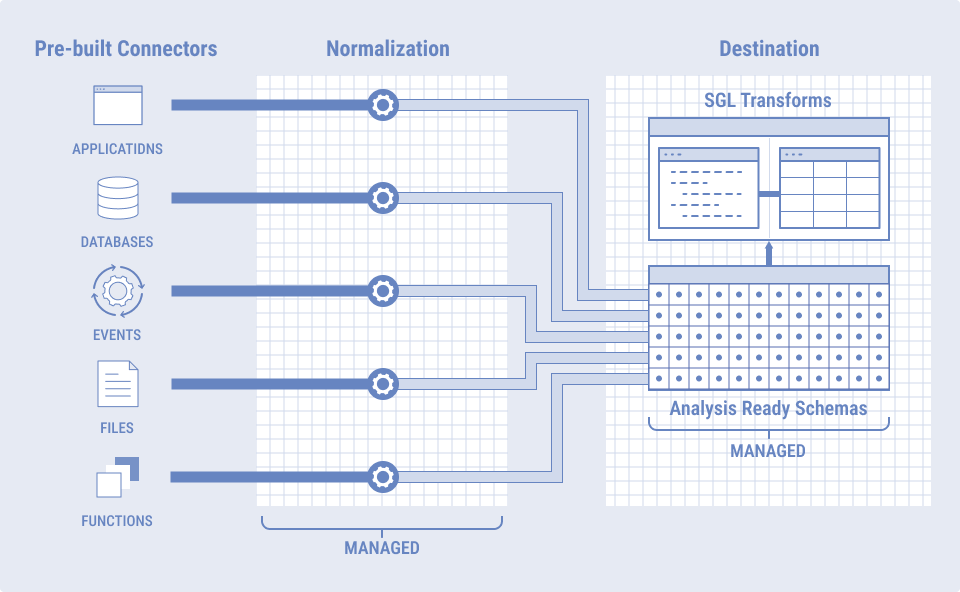
製品の特長としては、主に以下が挙げられます。
① 加工処理開発をSelect文だけで実現
dbtは、SQLのSelect文のみで「モデル」と呼ばれるデータ加工処理の単位を開発できるため、Pythonなどのプログラミング言語を使用することなく加工処理開発が可能です。
また、SQLで開発が可能なため、幅広いエンジニアに対応が可能で開発効率の向上が期待できます。
さらに、Macro・Jinja機能を活用することで、共通するSQL処理をテンプレート化し複数のモデル間で再利用できるため、保守性の向上や属人化の防止にもつながります。
② モデルの依存関係の自動管理
refと呼ばれる機能によって、モデル同士の処理の依存関係を明示的に定義することが可能です。
例えば、Aというモデルを先行して実行し、Aの実行完了後にBというモデルの実行を開始する。といった依存関係の構築が可能です。
また、依存関係を自動で可視化してくれるため、ユーザーはモデル同士の依存関係を簡単に把握することができます。
③ データ品質を一元管理
データ品質を維持するためのデータテスト機能によって、dbtで加工処理したデータの品質を容易かつ迅速にチェック・担保することが可能です。
また、source freshnessと呼ばれる機能を利用することで、データの更新状態を定期的に監視し、データ鮮度を把握することが可能となります。
さいごに
本コラムでは、モダンデータスタックの概要と、「Fivetran」、「dbt」という製品についてご紹介しました。それぞれの製品においては、挙げました特長が注目されており、現在多くの企業から導入についての相談が寄せられています。
当社では、長年培ってきたデータエンジニアリングのノウハウに加え、最新のモダンデータスタックに着目しその導入や活用を支援しています。同製品に対応可能な技術者は多数在籍しておりますので、導入や活用については是非当社までご相談ください。
執筆者

- 三田 航平
- ITプラットフォーム事業部 ビッグデータ統括部 ビッグデータビジネス担当 主任
- BIダッシュボード開発やデータエンジニアリング領域を得意としロジカルな思考と表現で顧客から好評を博す。データを愛しデータに愛された男。
監修

- 伊藤 大介
- ITプラットフォーム事業部 ビッグデータ統括部 ビッグデータビジネス担当 担当部長
- データ活用プロジェクトを多数経験したのち、現在はパブリッククラウドを活用した基盤構築案件の管理を中心に担当。現場経験を活かし、社内外のプロジェクト推進に取り組む。