当社は金融系のお客様に対し、既存のデータ分析基盤を対象に、Databricks を中心としたデータスチュワード支援を実施いたしました。
お客様のデータレイクには必要なデータが揃っていたものの、データ処理が Databricks と複数サービスに分散していたことで、運用効率や保守性、データ品質管理の面で課題が生じていました。処理フローの複雑化により、ガバナンスルールの統一も難しい状況でした。
さらに、以下のような具体的なニーズへの対応が求められていました。
- 契約情報を削除する仕組みが存在せず、対象者を正確に特定して安全に削除できる仕組みの構築が求められていた
- サービスが分散していたため、利用者のログイン操作が煩雑となり、利便性向上に向けた集約が求められていた
- Hadoop のサポート終了に伴い、既存の Hive ジョブを含む処理基盤を他環境へ移行し、将来のアーキテクチャを見据え、一元化と機能集約を進めることが求められていた
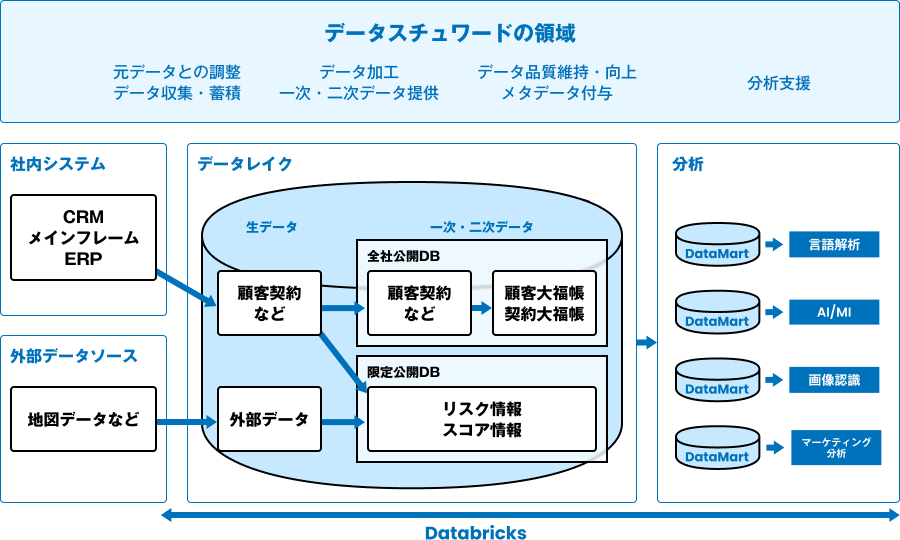
お客様は将来的にデータ処理を Databricks に集約していく方針を掲げており、システム全体の最適化とデータガバナンス強化を目的とした基盤整備を担当いたしました。
具体的には、以下の取り組みを組み合わせ、分散していた処理の整理と統制の取れたデータ運用環境の実現を図りました。
- 契約情報削除プロセスの自動化による運用負荷の軽減
- 既存 Hive ジョブの Databricks への移行による処理基盤の統一
- 外部データ参照のフェデレーション利用によるデータアクセスの柔軟化
これらの施策により、以下の効果を得ることができました。
- 手動作業に依存していた契約情報削除を自動化することで、運用負荷を大幅に軽減し、安全性とコスト効率を向上
- HiveQL/ORC 形式の処理を Databricks ワークフローおよび Delta テーブルへ移行し、スキーマ進化やタイムトラベルを活用できる柔軟性の高い基盤を実現
- フェデレーションとデータコピーを適切に使い分けることで、元システムへの負荷を抑えつつ、安定的なデータ提供を実現
- クラウド基盤への統合により、ガバナンスと監査対応の強化を図るとともに、将来的な改修コストを抑えながら拡張性の高い環境を整備
お客様の将来構想に寄り添いながら、データ基盤の整理とガバナンス強化を段階的に進めることで、運用効率と拡張性の両立を実現することができました。
当社は今後も、お客様のデータ活用をより安全かつ持続的に推進するためのパートナーとして、最適な基盤づくりをご支援してまいります。